


PRODUCT NEWS
New Breed of Safety Logic Solver Enhances Efficiency and Safety for Distillation Columns
A new breed of safety logic solver from Moore Industries enhances efficiency and safety for distillation columns.


View latest updates on Industrial Ethernet networking, the IIoT and Industry 4.0.

Full-range OPC UA solutions from the sensor to the cloud, showcased by Softing Industrial at embedded world 2024.
Learn More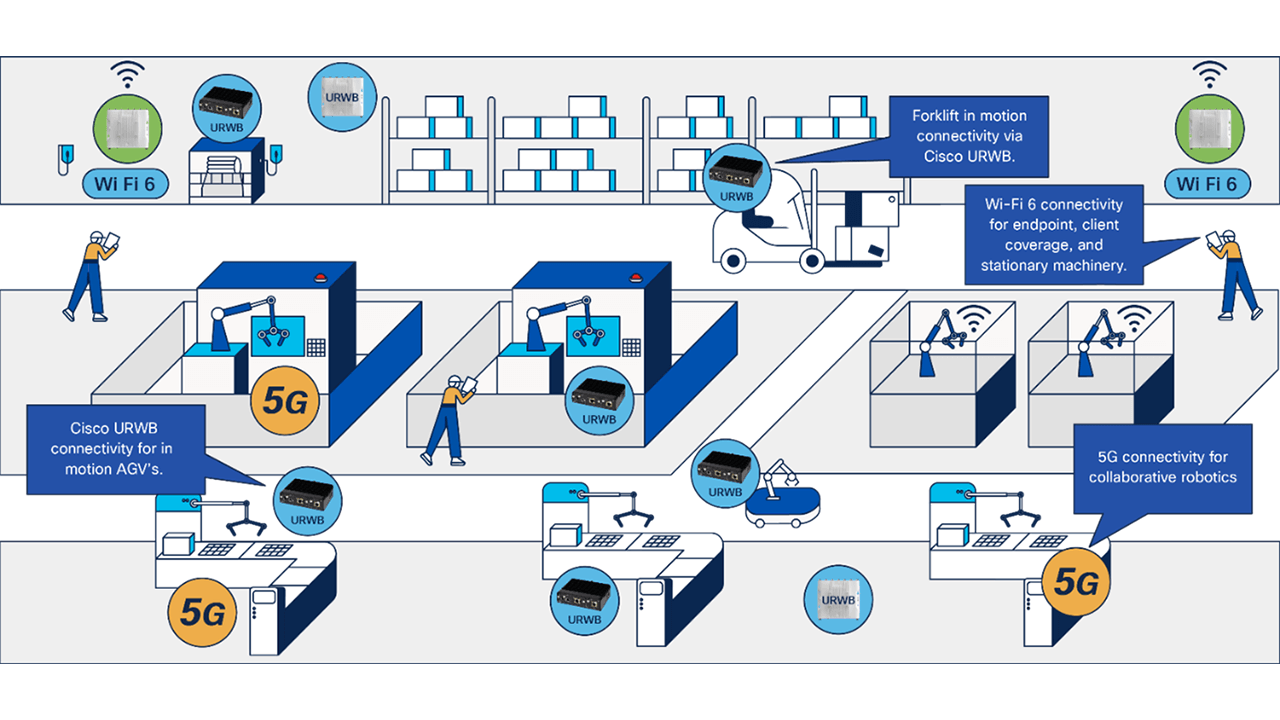
This article describes tomorrow’s smart factories, and how Cisco is delivering on this vision today with a unified …
Learn More
The development of Single Pair Ethernet (SPE) opens up a large number of new application possibilities for structured …
Learn More
Machine control networking is built on consistent data delivery of data between controllers, sensors and actuators. TSN is …
Learn More
Time Sensitive Networks in combination with Profinet provides mechanisms to form an optimal architecture for AI applications. Compared …
Learn More
With Time-Sensitive Networking creating a standard, unified network that supports different devices, IT and OT convergence are able …
Learn More
Industry experts agree that the foundation of Industrial Ethernet solutions for factory automation remains laser-focused on smart connected …
Learn More
As digital transformation accelerates, factories face both opportunities and challenges. New technologies are key to increased efficiency, but …
Learn More



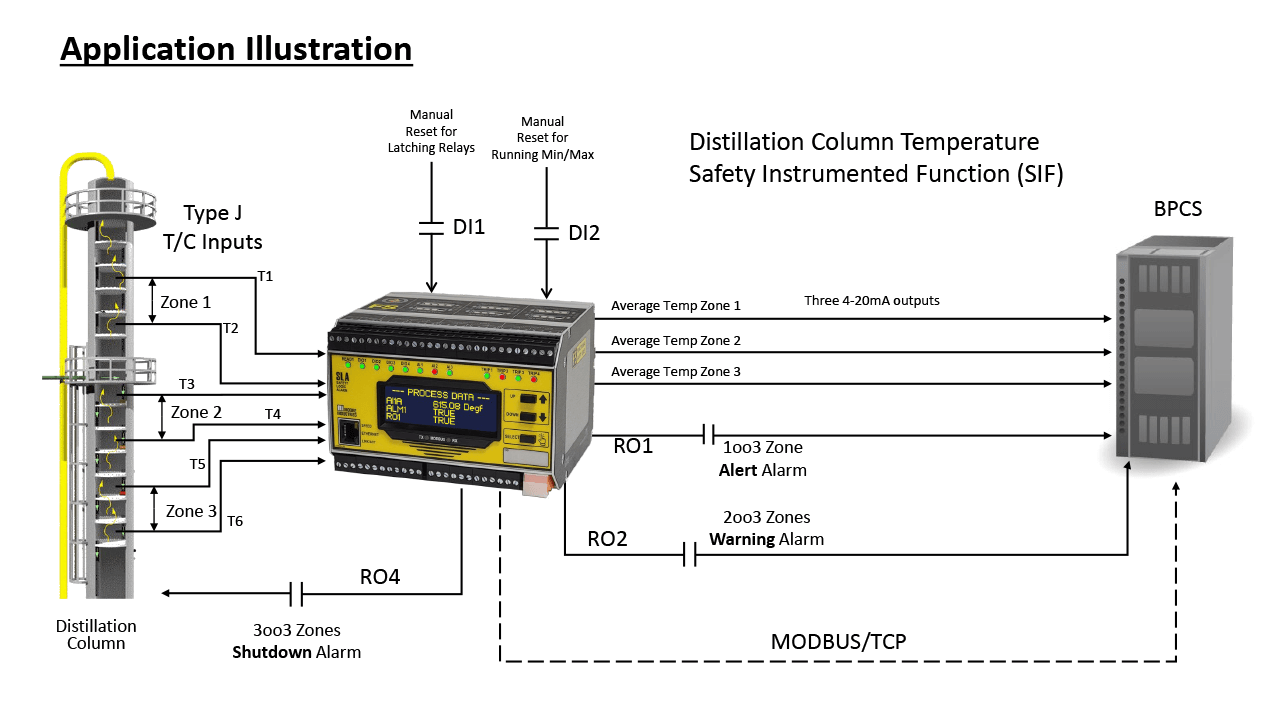
A new breed of safety logic solver from Moore Industries enhances efficiency and safety for distillation columns.

5G and Wi-Fi6/6E wireless technologies are now enabling standard, real-time communication in control processes, which was previously reserved exclusively for wired communication or proprietary wireless solutions.

Industrial cybersecurity has become an overarching, top priority for manufacturing as the move to the Industrial Internet of Things and cloud computing has created an environment where the traditional air-gap approach to security is not sufficient.

Join us in celebrating 50 years since Bob Metcalfe invented Ethernet technology, but "industrialized" Ethernet is also celebrating its own milestone after passing the quarter century mark.


The synergy of Single Pair Ethernet and OPC UA FX is enabling cloud connectivity for Ethernet-based end devices, and paving the way for a new era of industrial operation.
Learn More